







-366x243.png)




-366x243.jpg)
















|文/ SEO 分解茶|原文出處/SEO TEA-JavaScript SEO 終極指南(SEOer必看)|首圖/ freepik
本篇目錄 [隱藏]
為什麼 JavaScript SEO 越來越重要?
JavaScript 在近幾年來越來越興盛,主要的原因在於 JavaScript 能為網站帶來許多不同的特效,也為使用者體驗增加不少了效果。
而在美國,也有多達 80% 的電商網站使用 JavaScript 生成主要的內容,或是產生產品對應的連結,JavaScript 對於網站的必要性也是越來越大,所以與其為了 SEO 捨棄強大的 JavaScript,不如讓你的網站同時能擁有 JavaScript 也能做好 SEO。
就像 Google 的 John Mueller 所說:
https://twitter.com/JohnMu/status/894901485238190080
並不是說,SEOer 一定要學會 JavaScript 這項程式語言,相反的,每位 SEOer 都必須去了解 Google 如何處理 JavaScript 所產生的內容,並且適當的解決相關問題。- John Muller
Google 的搜尋引擎已經從早期的無法爬取 JavaScript 內容,到現在能夠渲染出 JavaScript 的頁面,Google 不斷優化著自己的搜尋引擎爬蟲,但仍有許多的不足是我們需要留意的。
而許多在做 SEO 的行銷人也常常在問:『搜尋引擎真的能夠爬取 JavaScript 嗎?』
帶著這個疑惑,本篇從 Google 爬蟲原理出發,到如何建立友善爬蟲的 JavaScript 網頁。
JavaScript 是什麼?
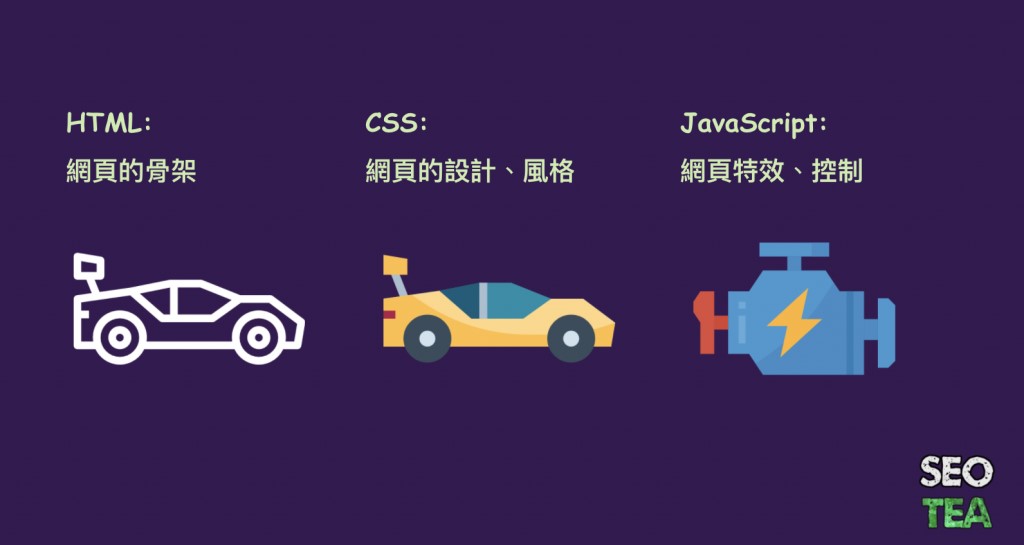
講到 JavaScript 就要先講到同為網頁語言的 HTML 跟 CSS 語法,這三個語法各別為網頁的呈現起到不同的作用:
- HTML:網頁的骨架,就像人體、又或是汽車,先有了骨架後,才可以開始長肉。
- CSS:可以說是長在骨架上的肉,或是汽車上的顏色。
- JavaScript:類似控制器,像是汽車的引擎、煞車、油門,替網站增加更多的運作與特效。
HTML 將網站的架構建好;CSS 為各個部分著色、提供不同的呈現;而 JavaScript 替網頁呈現出不同的特效,並依據使用者呈現不同的效果。於是乎此三種網頁語言,讓網頁的呈現變的完整且方便有趣。
哪些內容可能是 JavaScript 產生的呢?
- 主要內容
- 導覽列
- 內部連結
- 商品評論
- 分類篩選器
所以,如果這些內容在 JavaScript 上沒有處理好的話,很容易造成索引及排名上遇到困難。
如何檢查網頁上哪些內容是 JavaScript 所產生的呢?
透過 Chrome 擴充外掛檢查
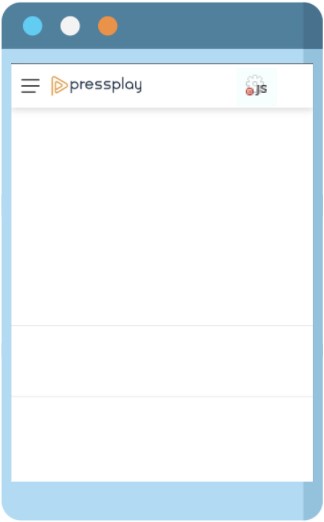
這邊介紹的工具叫做『Quick Javascript Switcher』,這個外掛可以直接開關網頁的 JavaScript 功能,只要你關掉 JavaScript 後,發現哪個部分的內容不見了,那很大程度就是那個內容是 JavaScript 所產生。
從下圖可以看到,當我們用外掛關掉 JavaScript 功能後,Pressplay 的主要內容消失不見了,那就代表說其中主要內容由 JavaScript 所產生。
從開發者工具關閉
首先按下滑鼠右鍵找到『檢查』,你會進入開發者介面。

接著使用指令『Control + Shift + p』 (Windows) 或是『Command + Option + p』 (Mac)。

接著在指令中輸入 JavaScript,就會看到一個『Disable JavaScript』選項,點擊即可關閉 JavaScript,同理要再打開只需使用相同指令再點擊一次便可打開 JavaScript 功能。
為什麼網頁原始碼沒有 JavaScript 產生的內容?
一般來說,我們在檢查網頁中的 meta 標籤、H 標籤等內容時,最常做的就是從網頁原始碼中去查看,也就是『右鍵 > 檢查原始碼』所呈現的內容。

而這個文件就是 HTML 文件,但這份 HTML 文件僅僅代表瀏覽器在解析頁面時的最初訊息,而 JavaScript 所產生的內容並不在一開始的 HTML 文件上。
所以,檢查網頁原始碼無法知道 JavaScript 更新後的動態內容。
此時就要介紹一下 HTML 加工後的 DOM 了,這邊為了不複雜化讀者理解簡單敘述一下,當你『右鍵 > 檢查』出來的東西便是加工過的 DOM(如下圖)。DOM 裡面會隨著你與網站的互動,將 JavaScript 所產生的內容加上去。
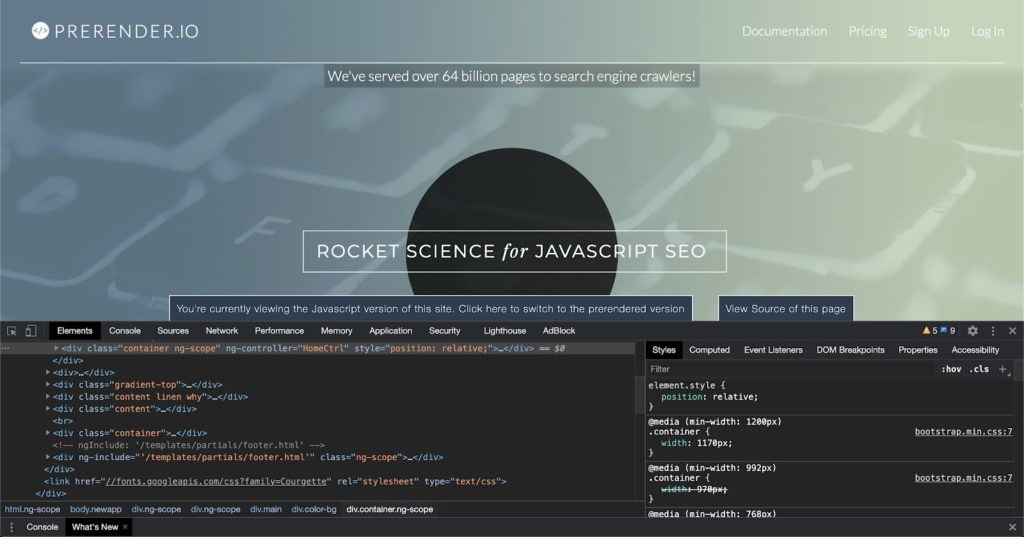
那如何區分 HTML 原始碼跟加工後的 DOM 呢?
原始碼(右鍵 > 檢視網頁原始碼)是食譜,食譜的作用在於告訴你料理的成分、如何做出這道料理,但他跟最後做出來的料理(烤雞)並不相同。
這份原始碼就是初始 DOM,如果網頁內容大多都由 JavaScript 產生的話,那很可能你的 HTML 原始碼只會有 Head、Footer 等資訊而已。
DOM(右鍵 > 檢查)是烤雞,廚師(使用者)最初會拿到一張食譜(HTML 原始碼),然後隨著廚師(使用者)的不同料理(點擊、滾動、篩選商品條件等),會產生不同樣貌的烤雞
而這隻烤雞就是加工後的 DOM,所以如果今天你要看 JavaScript 產生的程式碼的話,就需要從加工後的 DOM 去看。
p.s. 如果 Google 爬取頁面時無法完整呈現 JavaScript 產生的頁面,它至少可以索引為加載過的 HTML 原始碼。
在確認並且知道哪些內容屬於 JavaScript 所產生的之後,再來就是理解 Google 怎麼爬取 JavaScript,並且優化你的內容讓網頁排名上升。
Google 怎麼爬取 JS 網站?
對於搜尋引擎而言,JavaScript 一直是 Google 努力在改善爬蟲技術,讓搜尋引擎索引並排名的目標之一。雖然 JavaScript 為使用者帶來更良好的體驗及使用,但是對於搜尋引擎而言卻不是一件容易的事情,請記得:
Google 永遠不保證索引 JavaScript 的內容
根據 onely 網站調查指出,許多大品牌網頁上 JavaScript 之內容未被索引的情況:
- Nike 網頁上 JavaScript 所產生的內容有 22% 未被索引
- H&M 網頁上 JavaScript 所產生的內容有 65% 未被索引
- Yoox 網頁上 JavaScript 所產生的內容有 92% 未被索引
你可以想像,Yoox 在國外是知名電商網站,每個月可以有高達 1400 萬的流量,但是網站由 JavaScript 產生的內容竟然由高達 92% 是 Google 不會索引到的,由此可知這樣對 SEO 的影響可以有多大,損失又可以有多多。
但同樣的,也有把 JavaScript 所產生的內容處理的很好的網站,allrecipes.com 以及 boohoo.com 的網站分別讓 JavaScript 所產生的內容,被 100% 及 99% 的索引了,所以,只要方法得當,我們也能讓 JavaScript 與 SEO 兼顧。
Google 爬取頁面的過程
在早期搜尋引擎只需要下載 HTML 檔便可完整了解網頁內容,但由於 JavaScript 技術的崛起及普及,搜尋引擎甚至需要像瀏覽器一樣,以便他們以使用者的角度查看網頁內容。
而 Google 處理渲染的系統,被稱為 Web Rendering Service (WRS),中文可以翻譯成網頁渲染服務,後面以 WRS 代稱,而 Google 也給出了一張簡化的圖作為說明。
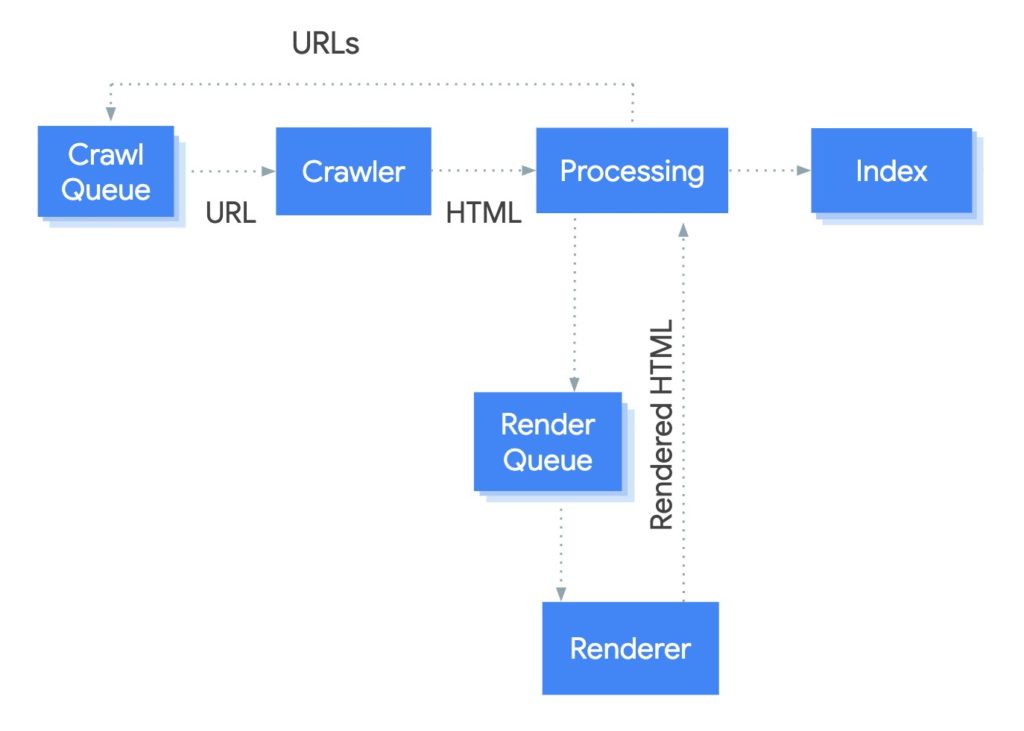
簡單說明 Google 爬取步驟,傳統爬取 HTML 檔頁面時,每項元素都很好爬取,整個索引並排名頁面的過程也迅速:
- Google bot 下載 HTML 檔
- Google bot 從原始碼中提取 url 網址,並快速訪問這些 url
- Google bot 下載 CSS 檔案
- Google bot 將下載下來的資源送到 Google 的 Indexer
- Google 的 Indexer 檢索頁面
但如果今天是爬取 JavaScript 所產生的網站內容的話,Google 會怎麼爬取呢:
- Google bot 下載 HTML 檔
- Google bot 在原始碼中找不到連結,因為 JavaScript 未被執行
- Google bot 下載 CSS 及 JavaScript 檔案
- Google bot 使用 WRS(渲染器,Indexer 的一部分)解析、編譯並執行 JavaScript 檔
- WRS 從外部 API、資料庫獲取資料(data)
- Indexer 可以索引內容
- Google 發現新的連結,並將其加入爬取排隊隊伍之中(Googlebot’s crawling queue)。至此,只是一般 Google bot 爬取 HTML 頁面的第二步而已。
可以發現,為了渲染出頁面,Google 多許多步驟。再來講一下渲染過程中,Crawler、Processing、Renderer 及 Index 之重要節點。
Google 爬取 JavaScript 過程中重要節點
Crawler(爬蟲)
首先,crawler 會先向伺服器發送一段請求(request),伺服器會丟出內容的檔案及其標頭(header),然後 crawler 將它儲存起來。
而由於 mobile-first indexing 的關係,發送請求的可能大多都是來自手機版的爬蟲(mobile user-agent),從 Google Search Console 上可以檢查到,你可以透過網址審查或是涵蓋範圍來知道現在是電腦版索引還是手機版優先索引的狀態。

然後有些網站會使用 user-agent detection,偵測使用者來到自己網站時,是用手機還是桌機、瀏覽器是什麼、瀏覽器版本的不同資訊,再根據這些資訊給使用者相對應的資訊,例如今天偵測到使用者是用手機版本的 chrome,便呈現手機版的頁面給使用者看。
需要注意的是,有些網站遇到爬蟲時可能會設定禁止該爬蟲爬取頁面,或是禁止特定地區 ip 的使用者查看頁面,這時候就要小心如果網頁沒設定好的話,很有可能爬蟲是看不到你的內容的喔。
記得從幾個方面測試看看 Google 爬蟲能否順利看到你的頁面:Google Search Console 的網址檢查器、手機友善測試工具以及複合式結果測試工具。
補充:從爬取過程那張圖可以看到,Google 將爬取後產生的頁面稱之為 HTML,但實際上,為了建構頁面內容,Google 其實爬取並儲存了相關所需的資源,像是 CSS 檔案、JS 檔案、API 端點、XHR requests等相關資源。
Processing(處理)
在 Processing 的過程中其實是非常複雜且處理很多事的,這邊重點講述 Google 處理 JavaScript 的過程。
1.遵循限制性最高的要求
什麼是限制性最高的要求,就是假設今天 Google 渲染(render)出頁面後,原本 meta robots 的資訊是 index 被加入了 noindex,那麼 Google 將不會索引其頁面,甚至其它尚未被渲染的頁面,因為 JS 產生 noindex 這類的語法,則可能導致頁面無法被渲染。
2.處理資源及連結(Resources and Links)
Google 並不像使用者那樣瀏覽頁面,Processing 的過程中有個很重要的工作便是檢查頁面上的連結(link)以及建構該頁面所需的檔案。
這些連結被拉出來,加到等待爬取的排隊序列中(crawl queue),反覆執行找連結、連結排隊、爬取連結,便是 Google 本身爬取整個網路世界的方式。
Google 透過 <link> 屬性,將建構頁面所需的資源,像是 JS、CSS 檔案拉出來。但是頁對頁的連結需要以特定的形式所呈現,才能被 Google 所抓取,那就是以 <a href=”連結”>的形式。
- <a href=”/good-link”>能被爬取的連結</a>
- <span onclick=”changePage(‘bad-link’)”>不能被爬取的連結</span>
- <a onclick=”changePage(‘bad-link’)” >不能被爬取的連結</a>
- <a href=”/good-1ink” onclick-“changepage(‘good-link’)”>能被爬取的連結</a>
如果你的連結是 JavaScript 所產生的話,那必須等到頁面被渲染後,爬蟲才能爬到。但有個風險就是,不一定頁面上的內容全數都能被成功渲染,有可能因為檢索預算不足的情況下渲染不到你的連結,所以務必留意連結的部分。
3.刪除重複內容(Duplicate elimination)
Google 傾向將重複頁面刪除,或者是降低重複頁面的爬取優先級別。許多 JavaScript 所產生的網頁,都會有個 app shell models,可以想像他是最小化的HTML、CSS 及 JS 所組成,用戶可以在不同需求下再載入所需要的內容。
但這有一個問題就是,app shell models 只有最簡單少量的內容及原始碼,所以很有可能被 Google 誤判為重複性內容,也造成其頁面能夠被渲染的優先級下降,正確的內容無法被索引,以及錯誤的頁面被排名。
4.緩存(caching)及其它
Google 下載頁面 HTML、CSS、JS 檔並渲染後,就會將其緩存。並且還有其它許多事情是 Google 會同時處理的,並不止於這些,但處理頁面的部分重點就在上述幾項。
Render queue (渲染序列)
接下來許多頁面即將被渲染, 所以在渲染排隊中,根據 Google 早期的說法,由於檢索預算的優化,渲染頁面並檢索會是比較後期的事,俗稱第二波索引(two waves of indexing),但其實在近期 onely 的 Bartosz Goralewicz 與 John 及 Martin 講述到,第二波索引的影響其實越來越小,Google 在等待渲染的中位數時間也只有 5 秒鐘,可見 Google 在渲染並索引這一塊下了相當大的功夫,未來渲染也將與檢索能夠同步進行。
Renderer(渲染器)
還記得前面說的食譜與料理嗎?頁面在渲染前的 DOM 跟渲染後的 DOM 就像料理的食譜,以及做好的烤雞一樣,簡單講 DOM 就是像圖中那樹狀圖所呈現。
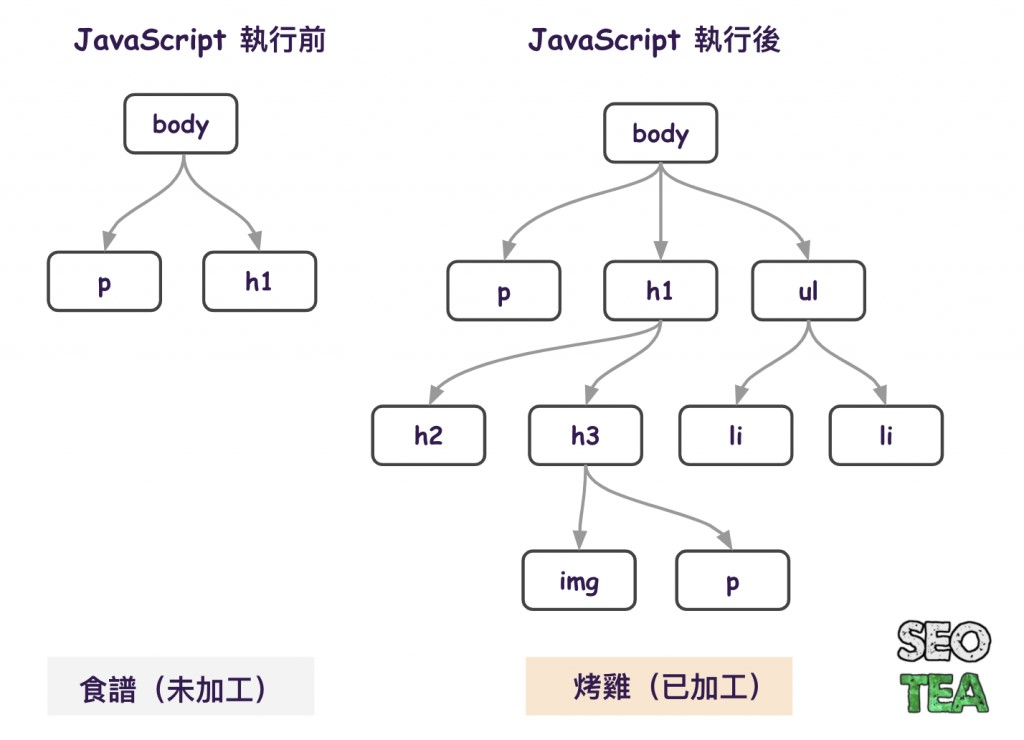
料理前的食譜是不會改變的,所以渲染前的頁面原始碼一樣不會因觸發 JavaScript 而改變,所以可以想像 Renderer 就是一個主廚,料理食譜並且產生一道料理(JavaScript 渲染出來的頁面),Renderer 為的就是去渲染出 JavaScript 相關內容。
要知道光是可以爬取整個網路世界成千上億的資料便是不容易,還要將其內容渲染出來耗費資源非同小可,根據 onely 指出,為了讓 JavaScript 內容被爬取、渲染並且索引,耗費的資源是一般 HTML 頁面的 20 倍,一定要格外小心。讓我們看看渲染器中有哪些重要的東西吧。
1.快取資源(Cache Resource)
Google 相當重度依賴快取,它會快取各種檔案,檔案快取、頁面快取、API requests 等,在被送到渲染器前就會先快取起來。因為不太可能每準備渲染一頁,Google 就下載一次資源,所以優先快取好的檔案資源就能快速渲染頁面。
但這也帶來幾個問題,有可能 Google 會快取到舊的檔案、舊版本的資源,導致在渲染頁面時出現錯誤。如果有這種狀況出現記得做好版本控制或是內容指紋,讓 Google 可以知道你更新了新的內容。
2.沒有特定逾時時間(No Fixed Timeout)
很多網上謠傳渲染器只會用 5 秒渲染你的頁面,但其實並不然,Google 渲染時可能會加載原有快取的檔案,會有 5 秒的這一說法,主要是因為網址審查工具相關工具,檢測頁面時需要獲取資源所以需要設立合理的逾時時間。
https://twitter.com/JohnMu/status/999580194582286336
為了確保內容完整呈現,Google 沒有特地設定逾時時間,但為了爬蟲爬取及使用者體驗,更快的速度一定是更好的。
3.渲染後,Google 看到了什麼?
這邊要提到一個很重要的點是,Google 並不會主動與網頁上的內容做互動,所以有些 JavaScript 的特效,需要使用者點擊或觸發的特效,是不會被 Google 所觸發,不會點擊更不會滾動頁面。
所以早期你們一定有聽過一個說法,不要使用瀑布流網頁的原因就是如此,因為 Google 不會捲動你也面的情況下,就無法觸發 JavaScript 所產生的內容,但 Google 也不笨喔,為了克服瀑布流,他們直接把機器人設定成一台超長版手機,這樣可以直接渲染出指定長度的內容。
可是一般需要 JavaScript 觸發的內容無法被 Google 渲染出來了喔,所以一定要特別注意,連結也不要出現 JavaScript 所產生之連結。

更多行銷人報導
【網站經營攻略】流量查詢、分析到成長秘訣,4 大熱門網站分析工具介紹
【網站經營攻略2】如何建置一頁式網站?提供給創業者、設計師與工程師的3種應用說明
|本文由SEO 分解茶授權提供,僅反映專家作者意見,未經原作者授權請勿轉載。
作者資訊

- 我們致力於提供台灣行銷從業者專業、實用的文章內容,若您也認同我們的理念,歡迎來信投稿:news@marketersgo.com
